6.1 Estimación de parámetros usando el paquete BioestadisticaR2
El paquete BioestadísticaR implementa cuatro funciones relacionadas con la estimación de parámetros y del tamaño mínimo de muestra. Estas son:
icm() proporciona el intervalo de confianza para estimar la media \(\mu\) de una variable aleatoria continua con distribución normal. También permite obtener la estimación de la media para variables aleatorias discretas cuya distribución pueda ser aproximada por la normal. En estos casos se considera la corrección por continuidad (cpc) \(\pm \frac{1}{2n}\)
nm() permite determinar el tamaño muestral necesario para que la estimación de la media poblacional tenga una precisión fijada de antemano.
icp()proporciona los intervalos de confianza para estimar la proporción binomial \(\pi\) según los métodos de Wilson, Wald y Agresti-Caffo (Wald ajustado), considerando la cpc apropiada.
np() permite determinar el tamaño muestral necesario para que el intervalo para la proporción binomial tenga una precisión fijada de antemano.
Veamos el uso de cada una de estas funciones con algunos ejemplos. Recordemos que se puede ver toda la información relativa a cada función, así como algunos ejemplos de su uso, escribiendo ?función() , por ejemplo, ?icm() proporciona ayuda -mostrada en el panel derecho de RStudio- sobre la función icm() (es necesario escribir ambos paréntesis).
6.1.1 Intervalo de confianza para la media de una variable aleatoria normal \(\mu\)
6.1.1.1 Función icm()
Como se ha indicado, esta función proporciona el intervalo de confianza para la media \(\mu\) de una variable normal. Los argumentos de esta función y, en su caso, los valores que asumen por defecto, son los siguientes:
x
vector de datos cuya media se va a estimar
n
tamaño muestral cuando se indican los datos resumidos
nivel de confianza (en tanto por uno). Este parámetro es alternativo a alfa, el error de estimación. Por defecto su valor es conf=.95.
alfa
alternativamente al nivel de confianza \((1-\alpha)\), se puede indicar el nivel error \(\alpha\) a través de este parámetro (siempre en tanto por uno). Por defecto su valor es alfa=.05.
decs
permite indicar el número de decimales en la presentación de resultados. Debe ser un valor entero y por defecto es decs= 3.
d
permite indicar la precisión deseada \(\delta\) para el intervalo de confianza. Si se especifica un valor d>0 la función invoca automáticamente a la función nm() para estimar el tamaño de muestra
vac
se trata de un valor lógico que por defecto es TRUE. En este caso, se está indicando que la variable aleatoria considerada es de tipo continuo. Si se especifica vac=FALSE la función asume que se está considerando una variable discreta y aplica una corrección por continuidad (cpc) al intervalo aproximado para estimar su media.
eco
se trata de un valor lógico. Si eco=TRUE (valor por defecto) la función genera un pequeño informe y no devuelve valores para poder ser asignados a otra variable. Si eco=FALSE, icm() omite el informe y devuelve los limites del IC y su precisión de forma que se puedan asignar a una variable.
Veamos brevemente su uso. La información muestral se puede especificar conforme a dos formatos:
Indicando el vector de datos a través del parámetro x.
Indicando el tamaño muestral n, la media muestral m y la desviación típica muestral s.
Comencemos con algunos ejemplos usando un vector de datos. En el primer ejemplo creamos una variable colesterol con ocho observaciones. Estimamos la media poblacional \(\mu\) utilizando el parámetro x.
Intervalo de confianza bilateral para la media de una VA normal
----------------------------------------------------------------
Información muestral:
No hay valores faltantes
Tamaño muestral: n = 8
Media: m = 202.188
Desviación típica: s = 18.837
Error estándar de la media: sem = 6.660
Estimación:
95%-IC(µ): (186.44, 217.935)
Precisión obtenida: 15.748
Como vemos, el intervalo se ha obtenido con un nivel de confianza del 95% (el valor asumido por defecto). Podemos establecer otra confianza indicándola a través del parámetro conf:
icm(x=colesterol, conf=0.90)
Intervalo de confianza bilateral para la media de una VA normal
----------------------------------------------------------------
Información muestral:
No hay valores faltantes
Tamaño muestral: n = 8
Media: m = 202.188
Desviación típica: s = 18.837
Error estándar de la media: sem = 6.660
Estimación:
90%-IC(µ): (189.57, 214.805)
Precisión obtenida: 12.618
También podríamos haber escrito icm(x=colesterol, alfa=0.10) y el resultado sería el mismo.
El vector de datos puede ser también una columna de un data.frame. Por ejemplo
icm(x=osteo$peso)
Intervalo de confianza bilateral para la media de una VA normal
----------------------------------------------------------------
Información muestral:
No hay valores faltantes
Tamaño muestral: n = 94
Media: m = 63.839
Desviación típica: s = 11.804
Error estándar de la media: sem = 1.218
Estimación:
95%-IC(µ): (61.422, 66.257)
Precisión obtenida: 2.418
En ocasiones, en lugar de disponer de los datos, como en los ejemplos anteriores, lo que se tiene es la información muestral resumida en forma de tamaño muestral, media y desviación típica. Esto es justo lo necesario para obtener la estimación para la media poblacional. Lo único que hay que hacer es especificarlo adecuadamente al invocar a la función icm(). Por ejemplo, si disponemos de una muestra de tamaño \(n=\) 50, de una variable arbitraria cuya media es \(\bar x=\) 75.3 y con desviación típica \(s=\) 16, el intervalo para estimar la media poblacional \(\mu\), suponiendo que la distribución de la variable es normal, se obtiene como sigue
icm(n=50, m=75.3, s=16)
Intervalo de confianza bilateral para la media de una VA normal
----------------------------------------------------------------
Información muestral:
Tamaño muestral: n = 50
Media: m = 75.300
Desviación típica: s = 16.000
Error estándar de la media: sem = 2.263
Estimación:
95%-IC(µ): (70.753, 79.847)
Precisión obtenida: 4.547
Como resulta obvio, los parámetros n, m y s aluden, respectivamente, al tamaño muestral, la media y la desviación. Ahora no se debe usar el parámetro x, reservado para referenciar vectores de datos. Si deseamos modificar la confianza, basta indicar su valor (en tanto por uno) con el parámetro conf, o equivalentemente el error, con el parámetro alfa, tal y como se vio en un ejemplo anterior.
6.1.1.2 Estimación del tamaño de muestra para estimar una media: función nm()
La función nm() permite estimar el tamaño de muestra necesario para obtener la precisión deseada en la estimación de la media poblacional. Los argumentos de esta función son exactamente los mismos que los de icm(). La precisión deseada \(\delta\) se especifica a través del argumento d. Por ejemplo, si deseamos saber el tamaño necesario para obtener una precisión de \(\delta=\) 3 unidades en el ejemplo anterior, podemos escribir
nm(n=50, m=75.3, s=16, d=3)
# Tamaño de muestra para la estimación de la media de una VA normal o su aproximación
# -----------------------------------------------------------------------------------
# Muestra piloto:
Tamaño muestral: n = 50
Media: m = 75.3000
Desviación típica: s = 16.0000
Error estandar de la media: sem = 2.2627
Precisión observada: d = 4.5471
# Estimación del tamaño muestral:
Precisión deseada: δ = 3.0000
Tamaño muestral necesario: n ≥ 115
resultando que necesitaríamos al menos 225 observaciones para que la precisión sea de 3 unidades. No olvidemos que esta estimación es una aproximación (no conocemos la varianza poblacional), y que con 115 casos no “garantizamos” esa precisión. La forma de proceder es aumentar la muestra actual de 50 casos a 115 y comprobar si la precisión obtenida con ella es de 3 unidades. Si no es así, volveríamos a estimar el tamaño necesario para consegirlo utilizando las nuevas medidas de síntesis de la muestra. En realidad, la función nm() puede invocarse de forma implícita a través de la función icm(). Basta indicar en esta última el valor de la precisión a conseguir a través de su argumento d:
icm(n=50, m=75.3, s=16, d=3)
Intervalo de confianza bilateral para la media de una VA normal
----------------------------------------------------------------
Información muestral:
Tamaño muestral: n = 50
Media: m = 75.300
Desviación típica: s = 16.000
Error estándar de la media: sem = 2.263
Estimación:
95%-IC(µ): (70.753, 79.847)
Precisión obtenida: 4.547
# Tamaño de muestra para la estimación de la media de una VA normal o su aproximación
# -----------------------------------------------------------------------------------
# Muestra piloto:
Tamaño muestral: n = 50
Media: m = 75.3000
Desviación típica: s = 16.0000
Error estandar de la media: sem = 2.2627
Precisión observada: d = 4.5471
# Estimación del tamaño muestral:
Precisión deseada: δ = 3.0000
Tamaño muestral necesario: n ≥ 115
Como se puede ver, el informe resultante glosa la información dada por las dos funciones, icm() y nm(), haciendo innecesario invocar de forma aislada a esta última.
Problema
Los niveles de glicoproteína CA-125 constituyen un marcador serológico de enfermedades inflamatorias o tumorales. En particular, su valor es elevado en el cáncer epitelial de ovario. En un estudio orientado a determinar los valores de CA-125 en ausencia de este tipo de patologías han participado 15 mujeres sanas. Los valores obtenidos de CA-125, expresados en U/mL, han sido los siguientes:
Se trata de determinar (a) el nivel medio de CA-125 que puede inferirse para la población de mujeres sanas; (b) el tamaño de muestra necesario para obtener una precisión de 1 U/mL.
Resolución
En primer lugar generamos el código en R para manejar la muestra:
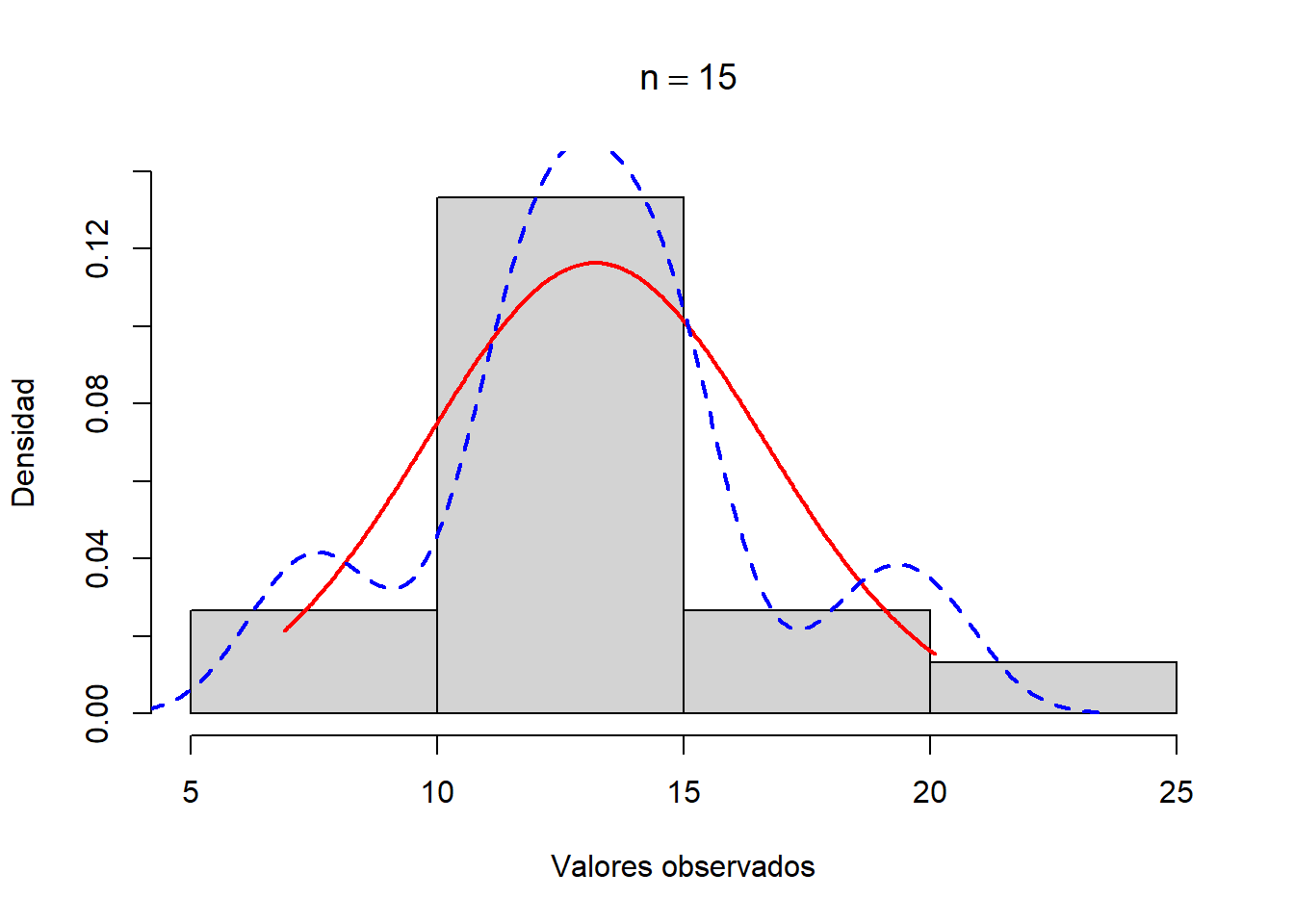
Siempre es conveniente visualizar los datos mediante algún diagrama. El paquete BioestadisticaR2 cuenta con la función testnormal() que representa el histograma y el modelo de distribución normal para poder comparar. Más adelante se interpretarán los resultados que muestra esta función. Recuerde que para poder acceder a ella es preciso tener habilitado el paquete (activándolo en el panel de paquetes de RStudio o bien escribiendo library(BioestadísticaR2))
testnormal(ca125)
# Test de normalidad de Shapiro-Wilk
-------------------------------------
n = 15, W = 0.964, p = 0.767
Como el nivel de CA-125 es una variable de tipo continuo que se está midiendo en personas sanas, podemos pensar que su distribución debe ser la Normal. Al representar los datos muestrales, aunque son pocos, no hay indicios para pensar en otra cosa, así que podemos considerar válida la inferencia sobre la media poblacional basada en la normalidad. Procedemos a hacerla
icm(ca125)
Intervalo de confianza bilateral para la media de una VA normal
----------------------------------------------------------------
Información muestral:
No hay valores faltantes
Tamaño muestral: n = 15
Media: m = 13.205
Desviación típica: s = 3.428
Error estándar de la media: sem = 0.885
Estimación:
95%-IC(µ): (11.307, 15.104)
Precisión obtenida: 1.898
El nivel medio de CA-125 en mujeres sanas de la población estudiada esperamos que sea un valor comprendido entre 11.307 y 15.104 U/mL con un 95% de probabilidad, o confianza. Al no haber especificado el nivel de confianza al llamar a la función icm(), se asume su valor por defecto, que es el 95%. La precisión obtenida ha sido, redondeando, de 1.9 U/mL. Como esta precisión es menor que la deseada en el enunciado, de 1 U/mL -el intervalo obtenido es más ancho, menos preciso-, será necesario estimar el tamaño de muestra necesario para conseguirla. Esto podemos hacerlo repitiendo la llamada a la función icm() especificando el valor deseado de la precisión icm(ca125,d=1) o bien invocando a la función nm() con los mismos argumentos. En el primer caso, se vuelve a obtener la salida de icm() y se añade la de nm(), que es la siguiente
nm(ca125,d=1)
# Tamaño de muestra para la estimación de la media de una VA normal o su aproximación
# -----------------------------------------------------------------------------------
# Muestra piloto:
Tamaño muestral: n = 15
Media: m = 13.2053
Desviación típica: s = 3.4282
Error estandar de la media: sem = 0.8852
Precisión observada: d = 1.8985
# Estimación del tamaño muestral:
Precisión deseada: δ = 1.0000
Tamaño muestral necesario: n ≥ 55
El resultado es que se deberían muestrear 30 casos más, para ampliar la muestra de 15 a 55 casos. Una vez hecho esto, hay que comprobar que la precisión obtenida es la deseada, ya que la fórmula de tamaño de muestra para estimar una media implica a la varianza de la variable analizada. Como esta es desconocida, se sustituye por su estimador muestral y esto implica que la fórmula no sea exacta, depende de la muestra considerada.
6.1.2 Intervalo de confianza para la proporción binomial \(\pi\)
6.1.2.1 Función icp()
La función icp() es análoga a la función icm(), pero ahora se trata de estimar el parámetro \(\pi\) de la distribución binomial (una prevalencia, por ejemplo). A continuación se indican los argumentos que maneja esta función:
x
puede ser un valor entero si se da la información resumida como x y n. Se trata del numerador de la proporcion binomial. También puede ser un vector de datos.
n
denominador de la proporcion binomial (si se da la informacion resumida)
level
debe ser un un valor entero o un texto. Se trata del valor o de la etiqueta del nivel de seleccion de x cuando este ultimo es un vector
conf
nivel de confianza \((1-\alpha)\). Por defecto conf=.95.
alfa
error de estimación \(\alpha\) (alternativo al parámetro conf, siempre en tanto por uno). Por defecto es alfa=.05.
decs
valor entero que indica la precision decimal para la salida de resultados. Por defecto decs=3.
d
valor real < 1. Permite especificar la precision deseada para el intervalo de confianza. Si se indica d>0, la función icp() invoca automáticamente a la funcion np()
tabla
Es un valor lógico. Si tabla=TRUE el informe de resultados adopta forma de tabla. En cualquier caso, la función devuelve los limites del IC y su precisión para poder asignarlo a otras variables.
Tal y como ocurría con la función icm(), la función icp() admite dos formas de especificar la información muestral:
Como un vector de datos (en el argumento x) y la clase de interés (en el argumento level)
De forma resumida, indicando el número de casos con la característica de interés (en el argumento x) del total de casos observados (en el argumento n)
Veamos algunos ejemplos. En el que sigue a continuación, definimos una variable sexo de tipo factor cuyos niveles son "M" y "H", y obtenemos la estimación para la proporción de mujeres ("M")
Intervalo de confianza para una proporción binomial
---------------------------------------------------
Información muestral:
Tamaño de muestra: n = 13
Estimación puntual clásica: p=x/n = 0.4615, q=(1-p)=0.5385
Casos observados: (nivel =M)x = 6
# Método exacto (Clooper-Pearson):
Pseudo-estimación puntual: p' = 0.4728, q'=(1-p')=0.5272
95%-IC(π): (0.197, 0.7487)
Semiamplitud: 0.2758
# Método de Wilson (con cpc):
Pseudo-estimación puntual: p' = 0.4714, q'=(1-p')=0.5286
95%-IC(π): (0.204, 0.7388)
Semiamplitud: 0.2674
# Método de Wald (con cpc):
No aplicable: x= 6 <20 , n-x= 7 <20
# Método de Wald ajustado (Agresti-Coull):
Estimación puntual: p=(x+2)/(n+4) = 0.4706, q=(1-p)=0.5294
95%-IC(π): (0.2333, 0.7079)
Precisión: 0.2373
La salida presenta una primera parte con el resumen de la información muestral y las estimaciones puntuales \(p=\hat\pi = \frac{x}{n}\) y \(q=1-p\). A continuación se indican los intervalos obtenidos por los métodos i) exácto de Cooper-Pearson, que siempre es válido; ii) aproximado de Wilson, válido si \(x>5\) y \((n-x)>5\) y en el que se incluye una cpc; iii) aproximado de Wald, válido si \(x>20\) y \((n-x)>20\), también con cpc y iv) el de Agresti-Coull (Wald ajustado), que es aproximado, no presenta condiciones de validez y suele funcionar bastante bien. Para cada caso, la salida indica la precisión, cuando los intervalos son simétricos (Wald y Wald ajustado), o la semiamplitud cuando no lo son (exacto y de Wilson).
Cuando la información disponible es el recuento de casos con la característica de interés de un total \(n\) de observaciones, es posible realizar la estimación invocando a esta función con los argumentos x (casos favorables) y n(casos observados):
icp(x=15, n=70)
Intervalo de confianza para una proporción binomial
---------------------------------------------------
Información muestral:
Tamaño de muestra: n = 70
Estimación puntual clásica: p=x/n = 0.2143, q=(1-p)=0.7857
Casos observados: x = 15
# Método exacto (Clooper-Pearson):
Pseudo-estimación puntual: p' = 0.2272, q'=(1-p')=0.7728
95%-IC(π): (0.1257, 0.3287)
Semiamplitud: 0.1015
# Método de Wilson (con cpc):
Pseudo-estimación puntual: p' = 0.2302, q'=(1-p')=0.7698
95%-IC(π): (0.1287, 0.3317)
Semiamplitud: 0.1015
# Método de Wald (con cpc):
No aplicable: x= 15 <20 , n-x= 55
# Método de Wald ajustado (Agresti-Coull):
Estimación puntual: p=(x+2)/(n+4) = 0.2297, q=(1-p)=0.7703
95%-IC(π): (0.1339, 0.3256)
Precisión: 0.0958
En este caso, todos los métodos resultan aplicables. El/la lector/a debe elegir el método que considere más conveniente, pero es importante que -al informar de los resultados- indique cuál de ellos ha sido.
6.1.2.2 Determinación del tamaño de muestra para estimar una proporción: función np()
La función np()es análoga a nm(), permite determinar el tamaño necesario para estimar una proporción binomial con la precisión deseada. Los argumentos de np() son los mismos que los de icp(). Vemos un ejemplo:
np(x=15,n=130,d=0.05)
Tamaño de muestra para estimar una proporción binomial
-------------------------------------------------------
Información muestral
Tamaño de la muestra: n = 130
Casos: x = 15
Inferencia para la proporción basada en el método de Wald ajustado:
95%-IC(π): (0.0705, 0.1832)
precisión observada: d = 0.0564 (5.64%)
Tamaño muestral requerido para δ = 0.05 (5.00%), conf.= 95%
- Basado en la muestra actual (po = 0.1832): n ≥ 230
- Sin considerar la información previa: n ≥ 385
Como ocurría con las funciones icm() y nm(), el cálculos del tamaño muestral puede ser invocado directamente desde la función de estimación de los intervalos, basta indicar la precisión deseada en icp(), así que el resultado anterior también lo podríamos haber obtenido escribiendo
icp(x=15,n=130,d=0.05)
Intervalo de confianza para una proporción binomial
---------------------------------------------------
Información muestral:
Tamaño de muestra: n = 130
Estimación puntual clásica: p=x/n = 0.1154, q=(1-p)=0.8846
Casos observados: x = 15
# Método exacto (Clooper-Pearson):
Pseudo-estimación puntual: p' = 0.1246, q'=(1-p')=0.8754
95%-IC(π): (0.0661, 0.1832)
Semiamplitud: 0.0585
# Método de Wilson (con cpc):
Pseudo-estimación puntual: p' = 0.1272, q'=(1-p')=0.8728
95%-IC(π): (0.0682, 0.1861)
Semiamplitud: 0.059
# Método de Wald (con cpc):
No aplicable: x= 15 <20 , n-x= 115
# Método de Wald ajustado (Agresti-Coull):
Estimación puntual: p=(x+2)/(n+4) = 0.1269, q=(1-p)=0.8731
95%-IC(π): (0.0705, 0.1832)
Precisión: 0.0564
Tamaño de muestra para estimar una proporción binomial
-------------------------------------------------------
Información muestral
Tamaño de la muestra: n = 130
Casos: x = 15
Inferencia para la proporción basada en el método de Wald ajustado:
95%-IC(π): (0.0705, 0.1832)
precisión observada: d = 0.0564 (5.64%)
Tamaño muestral requerido para δ = 0.05 (5.00%), conf.= 95%
- Basado en la muestra actual (po = 0.1832): n ≥ 230
- Sin considerar la información previa: n ≥ 385
Problema
Se desea estimar la prevalencia de las fracturas de cadera ocurridas en pacientes ingresados en hospitales de la Comunidad Autónoma de Andalucía en 2022. Para ello se muestrearon 500 ingresos, registrando un total de 37 fracturas.
Resolución
La prevalencia \(\pi\) de fracturas se estima de forma puntual a través de su frecuencia relativa observada \(\hat\pi=\frac{x}{n}\), siendo \(x\) el número de fracturas observadas (37) del total \(n\) de casos (500). Esta información es suficiente para obtener la estimación por intervalo de confianza. Para ello, usamos la función icp() tal y como sigue:
icp(x=37,n=500)
Intervalo de confianza para una proporción binomial
---------------------------------------------------
Información muestral:
Tamaño de muestra: n = 500
Estimación puntual clásica: p=x/n = 0.074, q=(1-p)=0.926
Casos observados: x = 37
# Método exacto (Clooper-Pearson):
Pseudo-estimación puntual: p' = 0.0766, q'=(1-p')=0.9234
95%-IC(π): (0.0527, 0.1006)
Semiamplitud: 0.024
# Método de Wilson (con cpc):
Pseudo-estimación puntual: p' = 0.0774, q'=(1-p')=0.9226
95%-IC(π): (0.0533, 0.1015)
Semiamplitud: 0.0241
# Método de Wald (con cpc):
Estimación puntual (clásica): p=x/n = 0.074, q=(1-p)=0.926
95%-IC(π): (0.0501, 0.0979)
Precisión: 0.0239
# Método de Wald ajustado (Agresti-Coull):
Estimación puntual: p=(x+2)/(n+4) = 0.0774, q=(1-p)=0.9226
95%-IC(π): (0.0541, 0.1007)
Precisión: 0.0233
La estimación puntual a través de la frecuencia relativa es \(\hat\pi=\) 0.074. También se puede usar la dada por el método de Agresti-Coull (no la justificamos aquí), que resulta ser \(\hat\pi´=\) 0.077. El intervalo exacto, basado en la distribución binomial, resulta ser \(95\%-IC(\pi)=\left( 0.0527, 0.1006 \right)\), es decir, que la prevalencia de fracturas debe de ser un valor comprendido entre el 5.3% y el 10.1% con un 95% de confianza. Los métodos restantes son aproximados. El de Wilson y el de Agresti-Coull son los preferibles, aunque el de Wilson requiere que tanto \(x\) (el número observado de fracturas) como \(n-x\) (el número observado de no fracturas) sean superiores a cinco. El método de Wald es el más extendido en la bibliografía y resulta ser la peor aproximación. Las opciones más recomendables pueden ser el método exacto o el de Agresti-Coull. Según este último, la precisión obtenida es del 2.33%, no esta mal. Si desearamos una precisión \(\delta=\) 1%, podemos estimar el tamaño de muestra necesario para ello incorporando esta información a la llamada a icp: icp(icp(x=37,n=500,d=0.01), o bien invocando a la función np(). En el primer caso, icp() se encarga de llamar a np(), mostrando la salida completa. En el segundo caso solo obtenemos la información referente al tamaño muestral.
np(x=37,n=500,d=0.01)
Tamaño de muestra para estimar una proporción binomial
-------------------------------------------------------
Información muestral
Tamaño de la muestra: n = 500
Casos: x = 37
Inferencia para la proporción basada en el método de Wald ajustado:
95%-IC(π): (0.0541, 0.1007)
precisión observada: d = 0.0233 (2.33%)
Tamaño muestral requerido para δ = 0.01 (1.00%), conf.= 95%
- Basado en la muestra actual (po = 0.1007): n ≥ 3480
- Sin considerar la información previa: n ≥ 9604
La estimación del tamaño muestral puede ser exacta (algo que no es posible en el caso de la estimación de \(\mu\)) o basada en la información muestral. En el primer caso, se trata de suponer que la varianza es la máxima posible (la correspondiente a una prevalencia del 50%), esto da lugar a una previsión de \(n\) que garantiza la precisión deseada, pero a costa de un tamaño a menudo inviable. En nuestro problema harían falta 9604 casos. Es esperable que una prevalencia no sea tan alta como un 50%. Si es menor, la varianza del estimador se reduce y esto permite mejorar la previsión del tamaño muestral. Para ello se utiliza la información de la muestra considerada, que actua como piloto. En nuestro caso, al considerar una prevalencia del 10% (el extremo del intervalo más próximo al 50%), la previsión del tamaño muestral es de 3480 casos. Muchos, pero son la tercera parte de lo que proponía la fórmula exacta. Lo único que hay que tener en cuenta es que esta fórmula, como ocurría con la usada en el caso de la media, esta basada en información muestral y, por lo tanto, no garantiza que con el tamaño estimado se obtenga la precisión deseada, habrá que comprobarlo.