2. ¿Cómo funciona la web?
Tal vez parezca una exageración, pero nosotros, quienes podríamos ser viejos usuarios de los ordenadores y de Internet, es posible que no tengamos del todo claros algunos conceptos importantes, aunque pensemos que así sea, sobre la WWW. Estas nociones son relevantes y dignas de ser tomadas en cuenta a la hora de construir nuestras propias páginas. Son 'cultura computacional' y nos dan plena conciencia de lo que en realidad estamos haciendo.
¿Qué es Internet?
Internet nos es otra cosa que una inmensa red de ordenadores que se comunican entre sí utilizando un mismo lenguaje, lo que permite que se entiendan unos a otros.
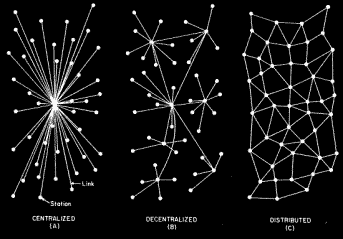
una descentralizada y una distribuida
No hay un 'Centro de Internet'. No hay un 'Ordenador Central', ni algo que tome el control o lo gobierne. Es una red distribuida. Cada uno de sus nodos es capaz de crear, enviar, y recibir información como cualquier otro. La razón se puede encontrar en sus orígenes, que tienen como base a una red concebida para ser funcional incluso después de un ataque nuclear. No hay un 'Centro de Control', ni máquinas más importantes que otras. No hay máquinas conectadas a ninguna máquina central. Todas están conectadas a sus vecinas, que a su vez están conectadas a sus propias vecinas. De tal manera que, siguiendo una ruta adecuada, puede llegar información de una máquina de la red a cualquier otra. Y no existe solo una forma de hacerlo.
Aunque prácticamente todos sus usuarios estamos acostumbrados a pensar en Internet como un inmenso conjunto de páginas web, esto no es así. Internet no es sólo páginas web, tiene multitud de servicios. No son de nuestro interés aquí, pero es bueno tener conocimiento de ello. La parte de Internet que nos interesa es, por supuesto, la WWW.
¿Qué es la WWW?
Es el acrónimo de World Wide Web, que más o menos significa "Telaraña mundial". A partir de aquí hay algo que debemos recordar: la Web son documentos enlazados unos con otros. Esa es la esencia de la Web. Por supuesto tiene que haber algún mecanismo que haga eso posible. Pensemos en todo lo que tiene que suceder cada vez que hacemos algo tan fácil como un click a un vínculo con el ratón. Cuando hacemos click, el ordenador recibe la orden de buscar el documento que se le ha pedido. Así que tiene que ir hasta donde esté el documento en cuestión, recogerlo, y mostrarlo en la pantalla.
Si nos ponemos en el lugar del ordenador, lo primero que necesitamos es saber qué documento tenemos que ir a buscar. Necesitamos saber dónde tenemos que ir a buscarlo, y una vez localizado, tenemos que traer el documento de algún modo a través de las redes de comunicaciones, y por último, tenemos que ser capaces de representar el documento en la pantalla. Desde el punto de vista técnico hay muchas operaciones, que en realidad no deben preocuparnos, pero las mencionamos porque desde el punto de vista del diseñador esto es importante. De aquí salen algunos conceptos que son fundamentales.
En primer lugar, cada documento debe tener un localizador o un identificador, algo que diga cómo se llama el documento y dónde se encuentra, es decir, en qué ordenador de todos los conectados a Internet está almacenado. En segundo lugar, debe existir un lenguaje en que los ordenadores se comuniquen para pedirse y entregarse documentos unos a otros. Y en tercer lugar, debe existir una forma de codificar los documentos para que una vez que el ordenador, sea el que sea, lo haya obtenido, sea capaz de representarlo en la pantalla o en cualquier otro medio.
Vayamos por partes. Empecemos por el localizador, es el nombre único que recibe cada documento en la red. Es muy sencillo: es lo que se pone en la barra de direcciones del navegador. Por ejemplo: http://www.google.com/
De momento lo importante es que si queremos crear un documento que esté enlazado con otro, tenemos que hacer referencia a él con su nombre: http://www.google.com/
Lo siguiente es la comunicación entre ordenadores. No profundizaremos aquí, pero es relevante darnos cuenta que ya la hemos visto actuar. ¿Alguna vez te ha salido en la pantalla eso de "Error 404: Not found" o algo por el estilo?
¡Pues ahí está!. Los ordenadores tienen una especie de protocolo sencillo
para comunicarse. Algo así: Me han dicho que tienes este documento. Dámelo,
anda
. Y la otra, si lo tiene, se lo da. Y si no lo tiene, le dice No lo
encuentro.
. Claro, los ordenadores hablan con números, y en vez de
decir No lo encuentro
dicen 404
. Así que tu ordenador vuelve
derrotado sin nada que entregar y un '404' en sus manos...
Este protocolo de comunicación consiste básicamente en unas cuantas reglas para que todo funcione bien, y unos cuantos códigos como "404", "500", "200", etc. Por cierto, el protocolo se llama HTTP, que significa HyperText Transfer Protocol (Protocolo para la Transferencia de Hipertexto). Lo de "Protocolo para la transferencia" se entiende. ¿Y la parte de Hipertexto exactamente qué quiere decir? No se, pero mi formación me dice que Hiper es un prefijo que usan los matemáticos para indicar que algo tiene dimensiones extras. Como en hiperespacio o hipercubo. El texto normal tiene una sola dimensión, así que hipertexto será un texto con más de una dimensión. Entonces hipertexto es como el texto normal, pero mejor: puedes salirte del hilo, porque no estás restringido a una sola dimensión. ¡Puedes ir dando saltos!
La tercera parte es el mecanismo para codificar los documentos de modo que los programas que reciben el documento puedan descodificarlo y representarlo en la pantalla como lo que era: un documento de hipertexto. Si los documentos fueran de texto normal, bastaría con enviar un fichero con las palabras del texto, un documento de texto normal y corriente. Pero no es así, es hipertexto. Eso quiere decir que además de palabras y frases, hay vínculos que se refieren a otros documentos. Entonces necesitamos un lenguaje para formatear los documentos que tenga en cuenta que hay palabras y también que hay hipervínculos.
El HTML es precisamente ese lenguaje. Es el lenguaje que se creó para compartir documentos en la Web. En aquellos entonces los recursos eran limitados, así que tanto el protocolo HTTP como el lenguaje HTML tenían que ser muy sencillos: por eso son tan sencillos. HTML significa HyperText Mark-up Language (Lenguaje para el Formato de Documentos de Hipertexto) ¿Mark-up significa "formato de documentos? Básicamente es eso. Es un término de imprenta. Cuando un escritor escribía un libro, a mano o con una máquina de escribir, y se lo entregaba a su editor, el editor tenía que marcar sobre el texto instrucciones para que los de la imprenta imprimieran todo correctamente: decía dónde estaban los títulos, las secciones, marcaba los párrafos, etc. Todo eso lo anotaba con unas marcas más o menos estándares que los de la imprenta entendían. Al conjunto de todas esas marcas, en inglés se le llama "markup".
Eso es justamente lo mismo que vamos a hacer cuando escribamos en HTML. Haremos el rol de escritor, pues redactaremos nuestros documentos. Y el de editor, pues vamos a decir dónde acaba y dónde empieza cada párrafo, cuáles son los títulos, dónde acaba y dónde empieza una lista y cada elemento de la lista, etc. El navegador será como la imprenta, que va a reconocer todas esas marcas y le va a dar a nuestros documentos la apariencia deseada: los títulos más grandes, los párrafos separados, las listas con marcadores de lista, etc.
Diferencia entre HTML y XHTML
Originalmente solo existía el HTML. De éste han surgido diferentes versiones, y todas con una más o menos completa compatibilidad hacia atrás con las versiones anteriores. La última especificación HTML que existe y existirá es el HTML 4.01. Después de ella se desarrolló una nueva implementación llamada XHTML 1.0. Cuando hablamos de XHTML 1.0 estamos hablando de HTML 4.x pues son lenguajes idénticos, salvo algunas diferencias que serán aclaradas en su momento. Éste documento hace un uso indistinto de los términos HTML y XHTML. Y cuando lo hace se refiere a las versiones mencionadas arriba. Las versiones HTML 4.01 Estricta y XHTML 1.0 Estricta, que son las utilizadas aquí, prohíben el uso de entidades y atributos que sólo tengan un fin puramente de presentación y de apariencia. Para el control de la apariencia se recurre al uso de tecnologías alternativas como son las Hojas de Estilo en Cascada CSS. De ahí que este Curso contenga tanto XHTML y CSS. Aclarado esto podemos comenzar.