
Práctica 1: La selección de los términos en el proceso automático de indización
En esta práctica el alumno deberá extraer los términos de indización de dos documentos de lenguaje natural. Estos documentos serán un par de resúmenes (uno en inglés y el otro en espańol), que contengan entre 80 y 100 palabras, obtenidos de las bases de datos disponibles en la facultad (p.ej. ISOC y Science Citation Index). Se recomienda que ambos textos correspondan a publicaciones relacionadas con la especialidad.
A estos textos se le extraerán las palabras carentes de significado. para ello el alumno deberá encontrar en la red un par de listas de palabras vacías (stopwords list), para inglés y espańol, o en su defecto una que sea multilíngüe y contenga a ambos. Este proceso se realizará en dos fases:
A - En una primera entrega se eliminarán las palabras vacías de ambos textos, con arreglo a las listas obtenidas.
B - En una segunda entrega se trabajará nuevamente con ambos textos, con la finalidad de detectar tres fenómenos:
1. Aquellas palabras que estando en la lista, tienen significado a los efectos del texto.
2. Aquellas palabras que no estando en la lista deberían ser eliminadas.
3. Los grupos de palabras que por su significado tienen sentido tratarlas como una unidad indisociable (sintagmas nominales). Este último fenómeno se verá con más detalle en la práctica 9.
Práctica 2: Cálculo y representación de la función de Zipf (k)
Partiendo de la relación de términos contenida en uno de los siguientes diccionarios de frecuencias léxicas:
Juilland, A. and Chang Rodríguez, E. Frequency dictionary of Spanish words. The Hague: Mouton; 1964.
Kucera, H. and Francis, W. Computational analysis of present-day american english. Providence, Rhode Island: Brown University; 1967.
Se calculará y representará la constante de Zipf (k):
constante (k) = frecuencia * rango
a fin de determinar por medios automáticos el conjunto de términos menos significativos en ambas lenguas. Los datos obtenidos deberán ser representados gráficamente con el fin de determinar el rango de valores medios, delimitado por los puntos cut-on y cut-off.
Práctica 3: Obtención de pesos tf.idf
Obtener los pesos de los términos pertenecientes a un conjunto de documentos a partir de la siguiente matriz de frecuencias.
|
T1
|
T2
|
T3
|
T4
|
T5
|
T6
|
T7
|
T8
|
T9
|
T10
|
|
|
D1
|
0
|
2
|
0
|
0
|
3
|
5
|
0
|
0
|
1
|
0
|
|
D2
|
1
|
4
|
0
|
1
|
5
|
7
|
1
|
0
|
2
|
1
|
|
D3
|
1
|
3
|
0
|
1
|
6
|
3
|
0
|
0
|
1
|
1
|
|
D4
|
2
|
2
|
1
|
0
|
8
|
2
|
0
|
1
|
0
|
1
|
|
D5
|
1
|
5
|
1
|
1
|
2
|
1
|
0
|
0
|
0
|
0
|
|
D6
|
0
|
6
|
0
|
0
|
4
|
5
|
1
|
0
|
1
|
0
|
|
D7
|
0
|
3
|
1
|
0
|
3
|
4
|
0
|
1
|
2
|
1
|
|
D8
|
1
|
2
|
1
|
1
|
9
|
2
|
1
|
0
|
1
|
0
|
| D9 | 0 | 7 | 1 | 4 | 0 | 0 | 2 | 3 | 1 | 0 |
La matriz también está disponible directamente en formato Excel.
La matriz de pesos debe ser creada aplicando la función tf.idf:
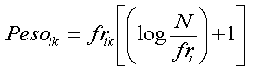
Práctica 4: Cálculo de la similaridad documental
Obtener la similaridad de cada uno de los documentos representados en la matriz de pesos realizada en la práctica 3. Las funciones de similaridad utilizadas serán tres: coeficiente del coseno, de Dice y de Jaccard. La función del producto escalar se encuentra integrada en las tres restantes.
Con cada función se realizará la mitad de matriz de similaridades. Posteriormente, se descompondrán las matrices en tres diferentes columnas y se construirá un gráfico en el que se representen la evolución de las tres funciones.
Producto escalar
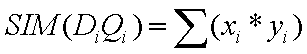
Coeficiente del coseno
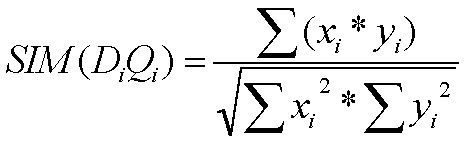
Coeficiente de Dice
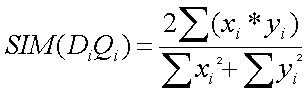
Coeficiente de Jaccard
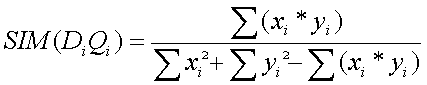
Práctica 5: Cálculo del valor de discriminación de un término
Calcular el valor de discriminación de cada uno de los términos de la matriz obtenida en la práctica 3. En primer lugar se calculará el valor de discriminación a través del método exacto. Este método consiste en medir la similaridad media de todos los documentos entre sí (Sm), teniendo presente que se utilizará como función de similaridad la del coseno. Posteriormente se elimina uno de los términos (i) y se vuelve a calcular la similaridad sin ese término (Sm-i). Finalmente el valor de discriminación de ese término será:
Vdi = Sm-i - Sm
Existe otro método llamado del centroide o aproximado. El centroide es un documento inexistente que se crea de manera artificial, calculando la media de todos los pesos en cada término. De esta forma, no es necesario calcular la similaridad entre cada par de documentos, sino solamente entre cada documento y el centroide. El resto del proceso es similar al caso anterior.
Finalmente se realizará una gráfica en la que se represente el valor de discriminación (calculado por ambos métodos), en función de las frecuencia total de cada término.
Práctica 6: Análisis de cluster
Partiendo de la matriz de similaridad hallada en la práctica 4, se deben clasificar los ocho documentos mediante un dendograma generado por el análisis de clustering que utiliza como regla de aglomeración al vecino más lejano (complete linkage), y otro con el del más cercano.
Práctica 7: Representación bidimensional de la información
Partiendo de la matriz dada, en formato Excel, se deben clasificar las distintas bibliotecas universitarias mediante un dendograma generado por el análisis de clustering que utiliza como regla de aglomeración al vecino más lejano (complete linkage). Para ello se utilizará el paquete estadístico SPSS.
Posteriormente se realizará un gráfico de Escalamiento Multidimensional (MDS). Los valores se calcularán con el paquete estadístico SPSS y posteriormente se representarán gráficamente mediante un gráfico de burbujas con el paquete Excel.
Práctica 8: Evaluación basada en la relación exhaustividad-precisión
En esta práctica se parte de la representación tabular de una serie de juicios de relevancia que el alumno obtendrá de diferentes motores de búsqueda. El alumno deberá aplicar el método de Salton para representar gráficamente la relación exhaustividad-presición y, de esta forma, concluir cual de los motores de búsqueda es más eficiente desde el punto de vista de los juicios de relevancia del usuario.
Práctica 9: Análisis morfosintáctico automático como preproceso para la indización (stemming y extracción de frases nominales)
Con el objeto de introducir al alumno en las técnicas lingüísticas que mejoran la indización automática, se le propondrá la realización del análisis de resultados de dos procesos lingüísticos: el análisis morfosintáctico y la extracción de sintagmas nominales. El primero de los procesos es un requisito para la reducción de las flexiones gramaticales a sus términos canónicos, mientras que el segundo es necesario para realizar por medios automáticos asociaciones de términos que resuelvan los problemas de ambigüedad que producen muchas veces las indizaciones de unitérminos.
1. La primera fase consistirá en localizar y estudiar las características técnicas del analizador morfosintáctico. El propuesto será el ENGCG de Lingsoft (Lingsoft. 1999. "ENGCG: Constraint Grammar Parser of English" [Página Web]. Consultada 22 Mar 1999. Disponible en http://www.lingsoft.fi/cgi-pub/engcg/). En la dirección suministrada se puede encontrar suficiente información sobre el funcionamiento del analizador así como sobre el significado de las claves que utiliza para construir la salida.
2. Una vez que el alumno se ha familiarizado con el funcionamiento del ENGCG, procederá a localizar un resumen en la base de datos LISA que someterá al analizador para estudiar su salida, tratando de identificar posibles errores, viendo la posibilidad de usar esta información de cara a un stemming. El objetivo final es que el alumno pueda identificar aquellos términos que han sido reducidos a su lexical y los que no. En el ejemplo siguiente se ofrece una muestra del análisis de una parte del resumen obtenido de la base de datos LISA. A partir de la salida del analizador se elabora la tabla que muestra aquellos términos que han sido reducidos en su versión canónica y en la flexión utilizada en el texto.
3. Una vez realizado el análisis morfosintáctico automático para el stemming, el alumno procederá, en la segunda fase del ejercicio práctico, a someter a un segundo resumen procedente de la misma base de datos del resumen anterior. En este caso la herramienta que deberá usar el alumno es el extractor de frases nominales denominado AZ Noun Phraser de la Universidad de Arizona (University of Arizona. 1999. "Artificial Intelligence Lab: demos" [Página Web]. Consultada 13 Aug 1999. Disponible en http://ai.bpa.arizona.edu/Multilingual/demos1_intro.html).